
Deutsche Startseite · English Homepage
STRAVID - Gemeinsam Software bauen.
Die Besserliste ist eine digitale Einkaufsliste. Sie zeigt die Prinzipien von Robuster Software in der Praxis. Durch die Reduktion von Abhängigkeiten und der Verwendung von altbewährten Technologien wird ein besseres Ergebnis erzielt, als es mit modernen Technologie-Stacks möglich wäre.
Lebensmittel einkaufen ist etwas, das fast jeder von uns regelmäßig tut. Diejenigen, die dazu noch in ein Geschäft gehen, verwenden in der Regel eine Einkaufsliste. Eine Gedankenstütze, die uns dabei hilft, nichts zu vergessen.
Meine Frau und ich kochen an den Wochenenden für die gesamte Woche vor. Dafür braucht es eine große Menge an Lebensmittel, die auf einer langen Einkaufsliste stehen. Die Einkaufsliste wird am Freitagabend geschrieben und samstags in aller Früh abgearbeitet.
Dazu wird der Einkaufswagen strategisch im Geschäft platziert, jeder wählt etwas aus der Liste aus, bringt es zum Einkaufswagen und streicht es von der Liste. Das wiederholt sich, bis die Liste leer ist und wir an der Kasse stehen.
Für ein solches Vorgehen hat eine Einkaufsliste aus Papier diverse Nachteile. Der Zettel und Stift verstecken sich gelegentlich unter den Lebensmitteln. Außerdem sind sie ein klassischer Flaschenhals in einem Prozess mit Gleichzeitigkeit. Wenn wir beide gleichzeitig zum Einkaufswagen zurückkommen, kommt es regelmäßig zu Wartezeiten, bis Stift und Einkaufszettel verfügbar sind.
Eine digitale Einkaufsliste hat diese Nachteile nicht. Sie lebt in der sagenumwobenen Cloud und jeder von uns kann sie auf seinem Smartphone sehen. Wir können unabhängig voneinander die Einkaufsliste abarbeiten. Wenn der eine etwas von der Liste streicht, verschwindet es bei dem anderen. Der Flaschenhals ist Geschichte.
Die App unserer Wahl nennt sich Überliste und ist bald ständiger Begleiter beim wöchentlichen Einkauf. Sie hat etwas, von dem wir gar nicht wussten, dass wir es benötigen.
Jedes Produkt gehört einer Kategorie an. Obst & Gemüse, Kühlregal, Theke und so weiter. Die Einkaufsliste selbst kann dann nach diesen Kategorien sortiert werden. Die Kombination aus diesen Funktionen erlaubt es uns noch effektiver einzukaufen.
Bereits mit unserer Einkaufsliste aus Papier haben wir uns das Geschäft in Bereiche unterteilt, um uns nicht in die Quere zu kommen. Ich übernehme das Kühlregal, meine Frau die Obst & Gemüse Ecke.
Auf der Papierliste war es umständlich herauszufinden, ob alles aus dem Kühlregal bereits im Einkaufswagen liegt. Die digitale Einkaufsliste hat das drastisch vereinfacht.
Die Überliste, das ist die Einkaufslisten App, hat jedoch auch massive Nachteile. Wir mussten feststellen, dass sie regelmäßig Daten verliert. Egal, ob beim Schreiben der Einkaufsliste oder dem Streichen von Produkten, vereinzelt verschwinden Einträge und tauchen plötzlich wieder auf.
Ohne den Quellcode zu sehen, kann ich nur mutmaßen. Die Symptome deuten für mich darauf hin, dass es unzureichende Schutzmechanismen im Kontext von Gleichzeitigkeit gibt. Befehle von unterschiedlichen Geräten überschneiden sich und heben vorherige Änderungen auf. Des Weiteren habe ich eine kontinuierliche Verschlechterung der Probleme beobachtet. Wenn durch wachsende Datenmengen die Antwortzeiten steigen, würde, dass die Probleme in Bezug auf Gleichzeitigkeit weiter verstärken.
Wir waren über diese Probleme nicht glücklich, haben uns aber damit arrangiert. Wie alle Benutzer:innen von mangelhafter Software sind wir besonders vorsichtig vorgegangen und haben die Finger von bestimmten Funktionen gelassen. Im Dezember 2021 ist jedoch das Fass übergelaufen.
Nach einem zweistündigen Fußmarsch durch einen Schneesturm mussten wir Zuhause feststellen, dass eine wichtige Zutat fehlt. Eine Zutat, die mit Sicherheit auf der Liste stand und dann heimlich von der Überliste verloren wurde.
In diesem Moment, erschöpft und wütend, beschloss ich eine eigene digitale Einkaufsliste zu entwickeln.
Nach über 10 Jahren kommerzieller Softwareentwicklung und unzähligen Anwendungen im Sinne der digitalen Selbstversorgung war der Name schnell gefunden: Besserliste.
Eine Anspielung auf die zu ersetzende App Überliste und die Tatsache, dass ich es besser kann. Das klingt überheblich, hat aber leider mehr mit dem Zustand der Software-Branche zu tun als mit meinem Ego.
Neu entwickelte Software ist meist langsamer, Ressourcen hungriger und fehleranfälliger als früher, obwohl die Geräte und Internetanbindungen leistungsfähiger sind.
Als Mensch, mit Blick hinter die Kulisse weiß ich, dass es dort nicht besser aussieht. Moderne Software zu warten und weiterzuentwickeln, ist ein Kraftakt.
Robuste Software ist ein Sammelbegriff für Ideen und Ansätze, wie bessere Software entwickelt werden kann, die weniger von diesen Problemen geplagt ist.
Der Kernbegriff von Robuster Software ist Reduktion. Das Entfernen von Abhängigkeiten und Komponenten macht ein System stabiler. Das steht im krassen Gegensatz zum Vorgehen der meisten Softwareentwickler:innen. Die meisten kombinieren Frameworks, Open Source Komponenten, Build Systeme und AWS Dienste anstatt selbst programmieren.
Langweilig ist ein fast genauso wichtiger Begriff. Altbewährte Technologien sind ein ausgezeichnetes Fundament für Projekte, die dem Zahn der Zeit widerstehen sollen. In unserer Branche ist die Entscheidungsgrundlage zu oft der Lebenslauf anstatt der Zweckdienlichkeit. Durch eine grundlegende Tendenz zum alten, langweiligen erspart man sich viel Künstliche Komplexität und Ärger.
Nach diesem Diskurs über Softwareentwicklungs-Prinzipien widmen wir uns jetzt der konkreten Entwicklung der Besserliste.
Nach der Namensfindung wurde sofort die zweitwichtigste Aufgabe eines jeden Softwareprojektes abgehakt: Mit den Menschen reden, die die Software verwenden werden.
In diesem Fall war das einfach. Ein Selbstgespräch und einem Austausch mit meiner Frau später war klar, was wir wollen.
Nach der Unzuverlässigkeit der bisher verwendeten App ist es kein Wunder, dass Datenkonsistenz an oberster Stelle steht.
Performance ist nicht so greifbar wie ein konkretes Feature, aber deshalb nicht weniger wichtig. Das Umfeld, in dem wir die Anwendung verwenden, gibt in diesem Fall die relevanten Eckdaten vor.
Meine Frau verwendet ein altes iPhone 5S. Ich besitze zwar schon ein moderneres iPhone 8, kann aber nur 3G verwenden. Die digitale Einkaufsliste muss also auf leistungsschwachen Smartphones mit kleinem Bildschirm und schlechter Internetverbindung zurechtkommen.
Mit einem Breadboard wird erkundet, welche Ansichten und Elemente für die gewünschte Funktionalität nötig sind. Zudem visualisiert es die Zusammenhänge und Abfolgen in der Anwendung.
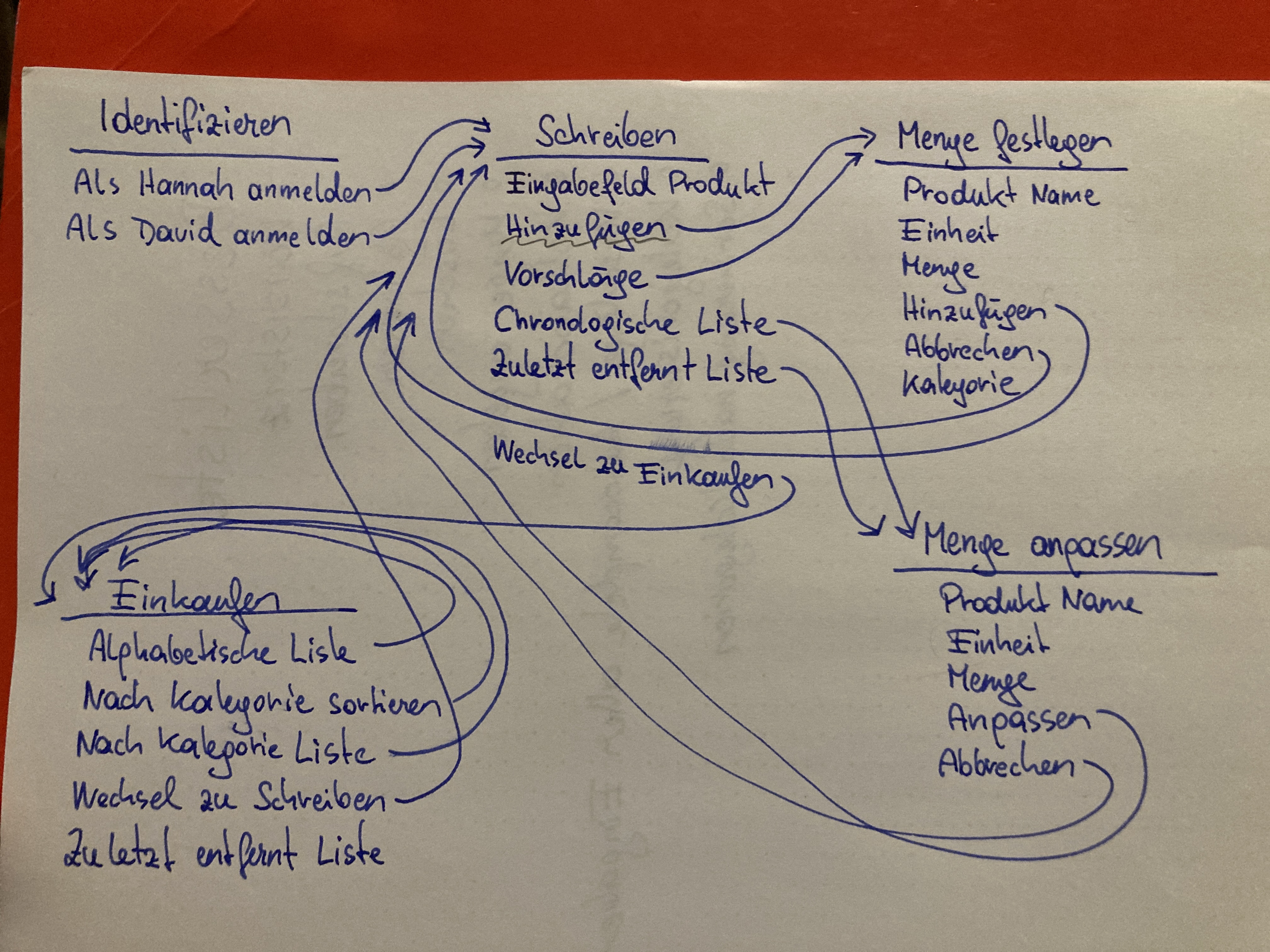
Ein Breadboard erlaubt es schnell und günstig Feedback zu sammeln. Wie ein Statechart kann es Sackgassen und fehlende Elemente aufzeigen. Probleme zeigen sich lange, bevor Zeit in UI Entwürfe und Quellcode investiert wird.
Im Vergleich mit dem Endergebnis hat sich nur wenig verändert.

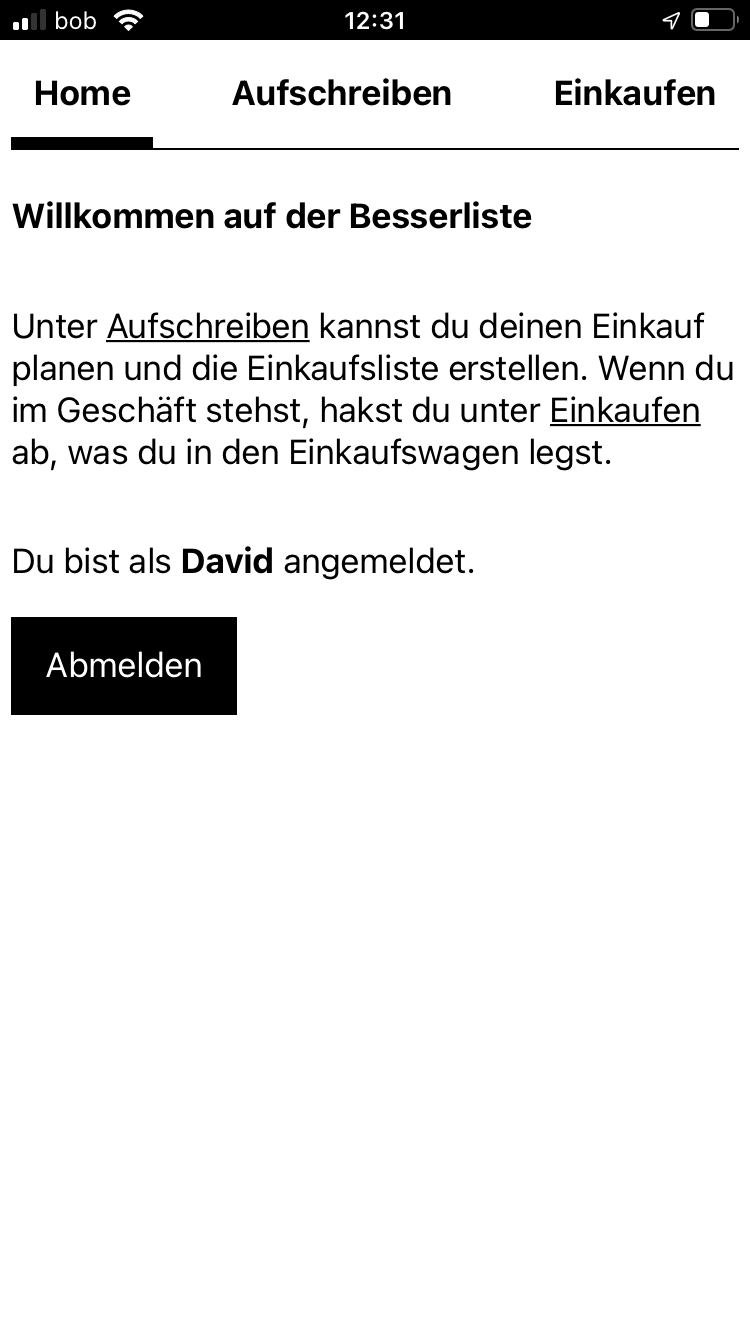

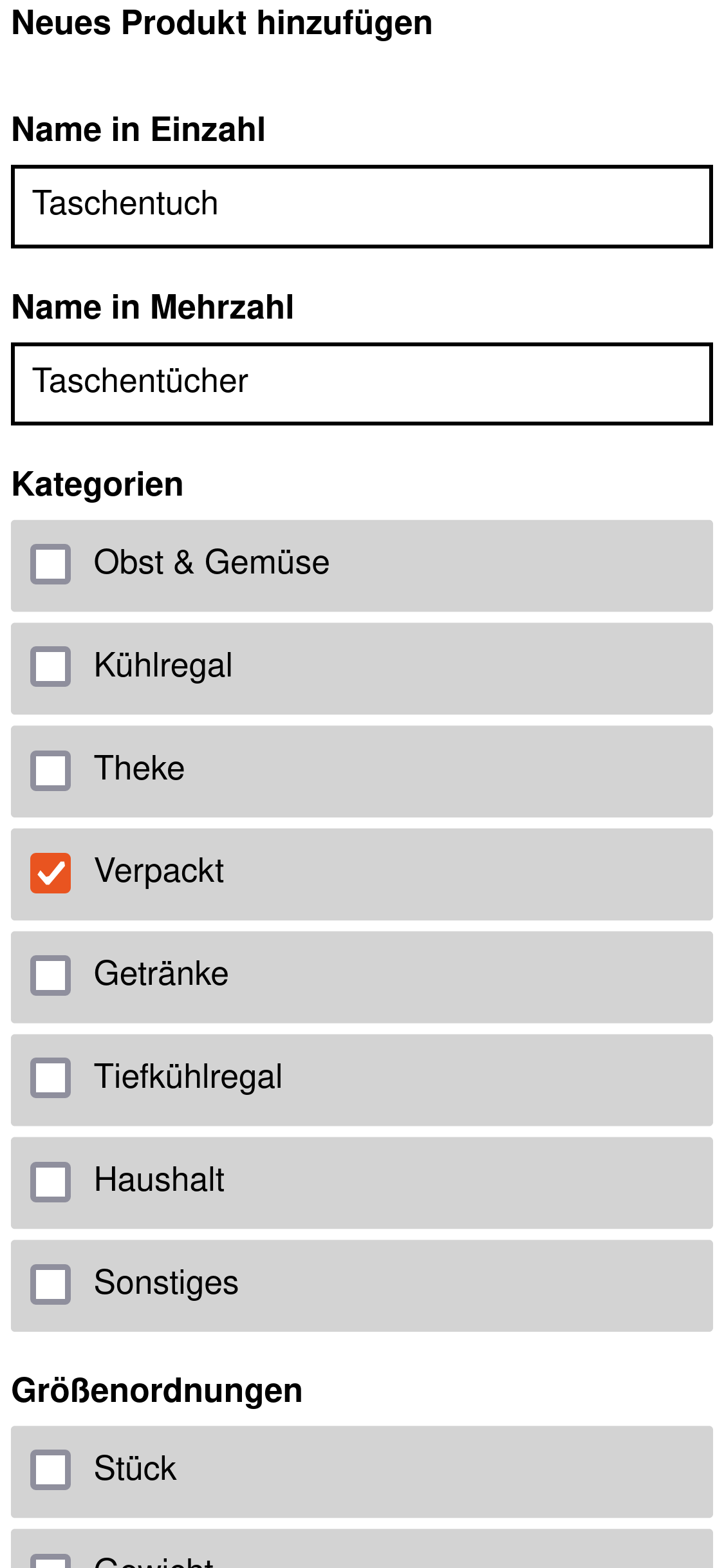
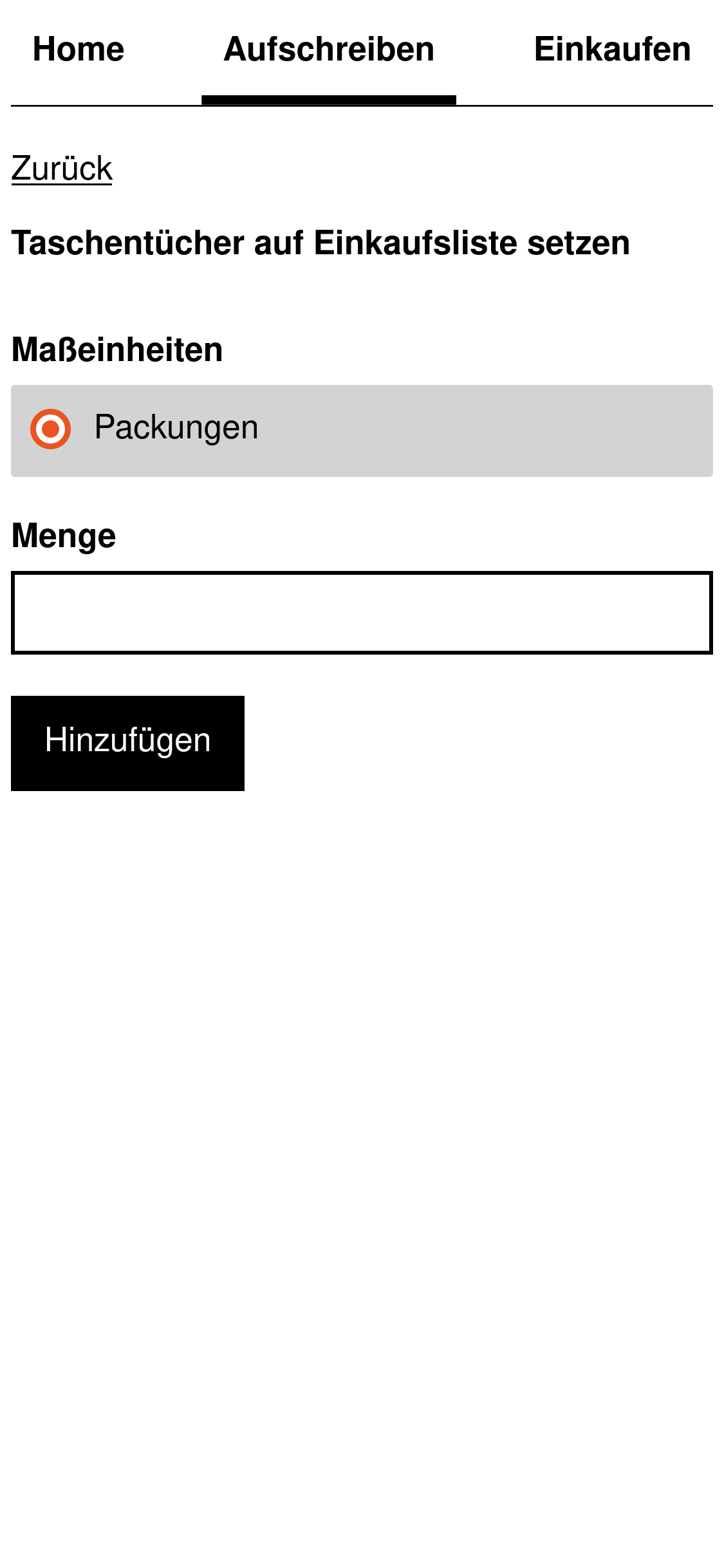
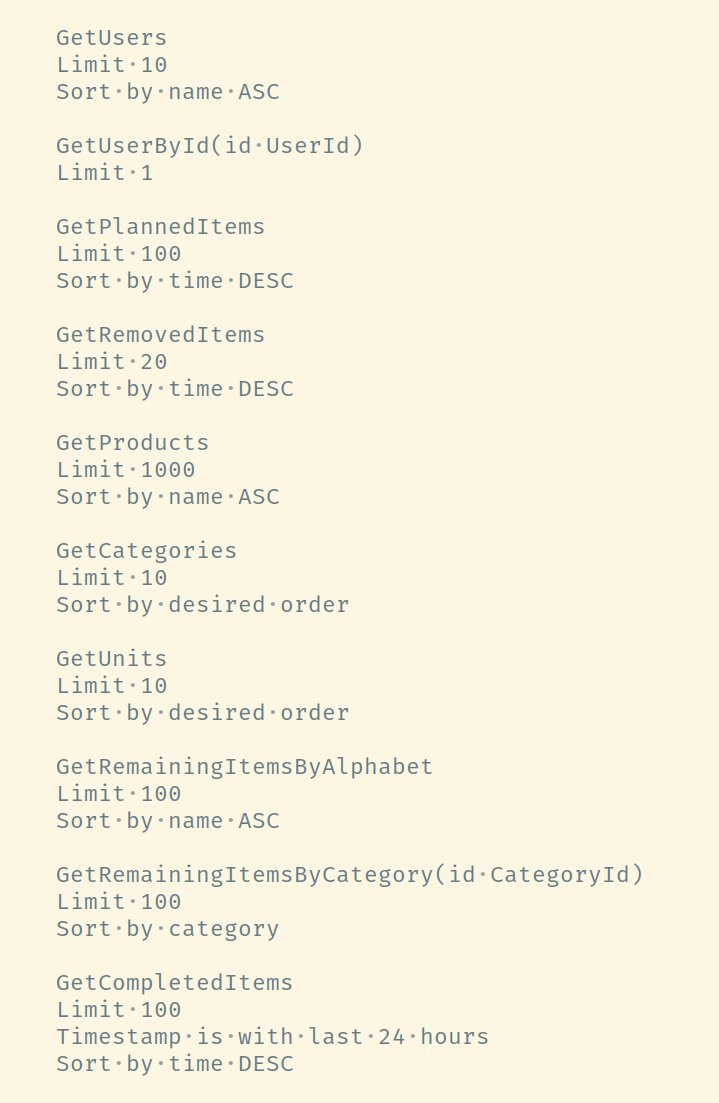
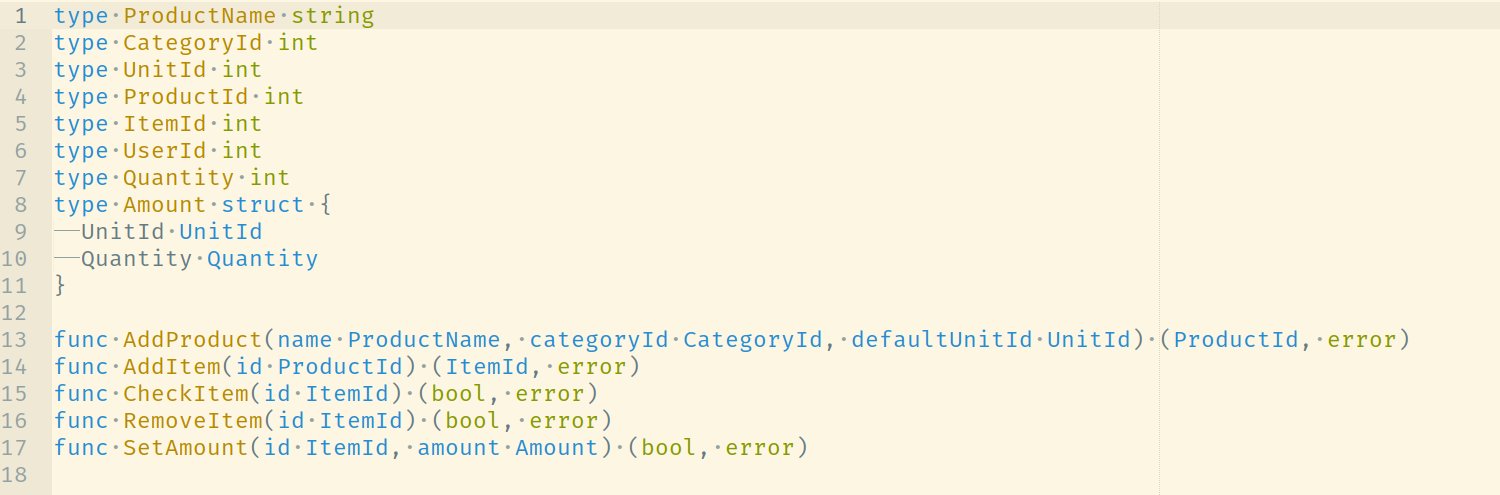
Die Interaktionen zwischen Mensch und Einkaufsliste lassen sich in zwei Kategorien teilen. Abfragen liefern Informationen über das System. Mit Anweisungen wird der Zustand des Systems verändert.
Dieser Zugang führt zu einem Vokabular, das sich an der Sache orientiert und auch von Nicht-Technikern verstanden wird. Das erleichtert die Kommunikation und macht Nuancen in der Domäne sichtbar. In Anwendungen mit klassischer CRUD-Architektur fehlt diese Ähnlichkeit zwischen Quellcode und Anwendungsgebiet. Es kommt schneller zu Missverständnissen, die Implementierung entfernt sich zunehmend von den Anforderungen und oft passiert es, dass die Technik zunehmend den Ton angibt.
Diese verkehrte Welt lässt sich schon in der Planung kostengünstig verhindern. Basierend auf dem Breadboard kann ein Großteil der benötigten Abfragen und Anweisungen niedergeschrieben werden.
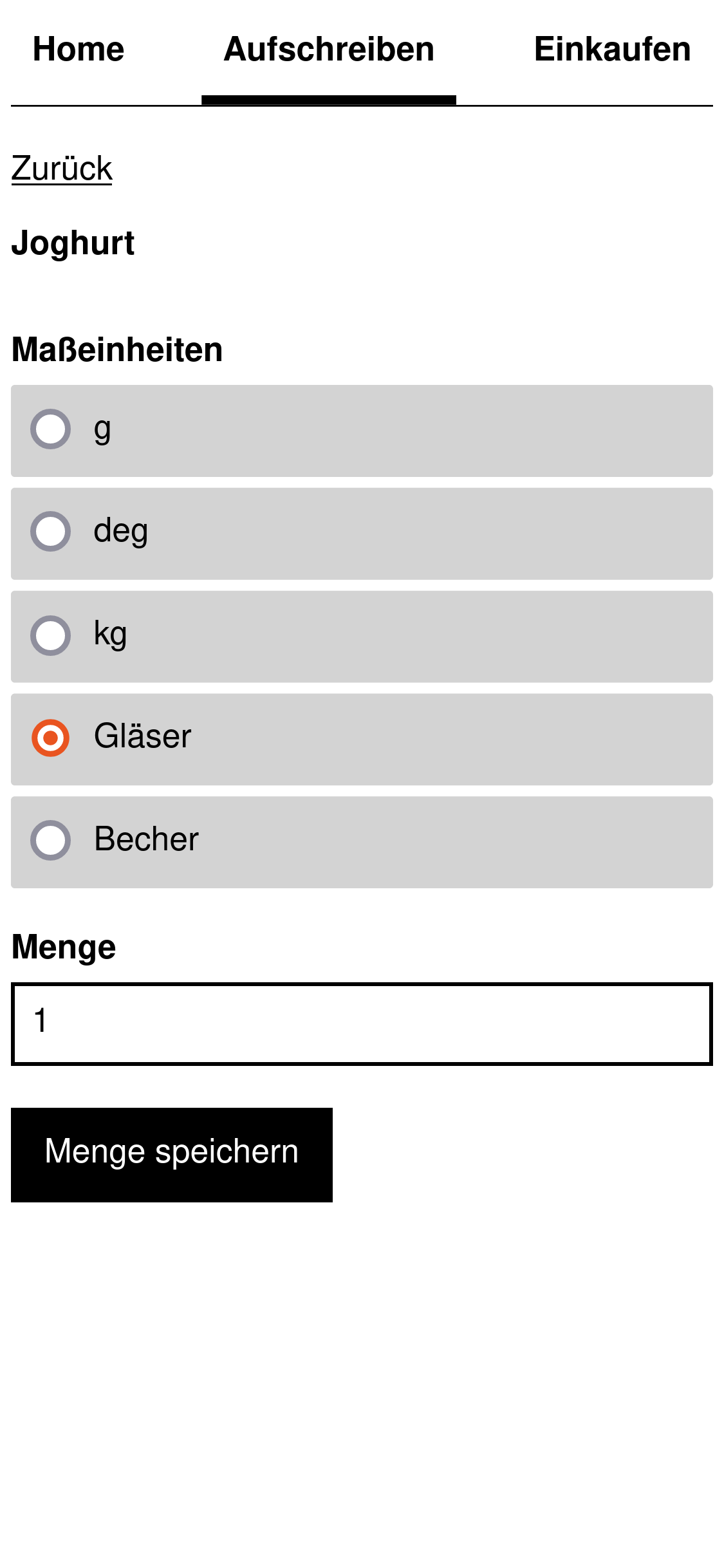
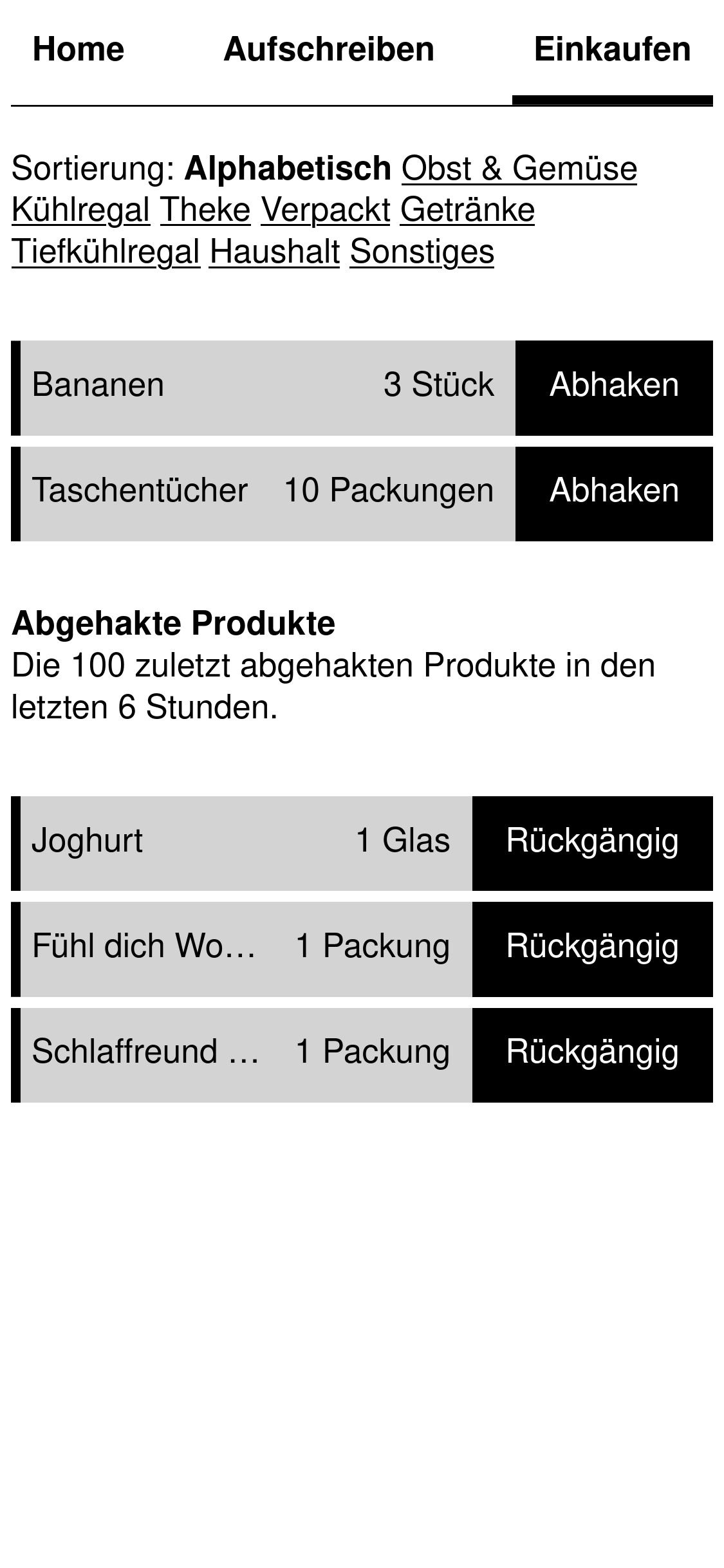
Auf den folgenden Screenshots sind die geplanten Abfragen und Anweisungen zu sehen. Hervorzuheben sind die Angaben zu Limits und Sortierung bei den Abfragen. Jede Abfrage muss die Menge an Information limitieren und eine Sortierung festlegen.
Das garantiert die Stabilität in der Zukunft. Wachsende und sich verändernde Datenmengen können bei ungebundenen Abfragen zu Problemen führen. Zusätzlich werden durch diese Angaben wichtige Erkenntnisse für das Datenbankschema gewonnen.
Ein konkretes Beispiel: Die Abfragen für Kategorien und Maßeinheiten haben aufgezeigt, dass es in beiden Tabellen extra Spalten geben muss, nach denen sortiert wird.
Jedes System kommt einmal an sein Limit. Sind diese Limits nicht vorab bekannt, werden sie erst im Echtbetrieb gefunden. In der Regel passiert das zu einem ungünstigen Zeitpunkt.
Deshalb wird ein System vorab dimensioniert. Wenn bekannt ist, mit welchen Datenmengen und Bedingungen das System funktionieren muss, können bereits vor dem Echtbetrieb Leistungstest durchgeführt werden. Auf diese Weise identifizierte Flaschenhälse können in aller Ruhe entfernt werden.
Meine Frau und ich wollen die digitale Einkaufsliste für die nächsten 50 Jahre verwenden. Wie schon zu Beginn erwähnt, machen wir einen wöchentlichen Großeinkauf. Dabei landen nicht mehr als 100 Gegenstände im Einkaufswagen. Insgesamt sollten 1.000 unterschiedliche Produkte ausreichen, um alle uns bekannten Rezepte kochen zu können. Außerdem wird es nicht mehr als 10 Benutzer:innen geben.
Die maximalen Längen für Benutzername, Kategorie, Maßeinheit müssen nicht unbedingt limitiert werden, da sie im System vorab hinterlegt sind. Bei Produktnamen ist das anders. Als freie Benutzereingabe ist es wichtig, hier ein Limit zu definieren. „Eierschalensollbruchstellenverursacher“ ist der längste Produktname, der uns eingefallen ist.
Mit diesen Eckdaten kann berechnet werden, unter welchen Bedingungen das System funktionieren muss.
Nach der Planung und dem Design des Systems geht es in die technische Umsetzung. Die Freude auf diesen Arbeitsschritt ist groß, endlich wird programmiert. Genau jetzt ist jedoch größte Vorsicht geboten. Viel zu oft werden Technologien und Architekturen gewählt, basierend auf der Laune der Entwickler:innen statt den Anforderungen. Die Sucht nach Neuem kombiniert mit fantastischen Marketingversprechen führen schnell zu Künstlicher Komplexität.
Diese lenkt nicht nur vom eigentlichen Ziel der Anwendung ab. Sie arbeitet in der Regel aktiv dagegen. Überflüssiger Quellcode macht das gesamte Projekt langsamer, schwerer zu verstehen. Jede Abhängigkeit erhöht die Chance auf zukünftige Arbeit, wenn der Zahn der Zeit unwiderruflich gewinnt.
Deshalb ist es so wichtig, sich auf die Prinzipien von Robuster Software zu fokussieren. Die Anzahl an Technologien auf das Minimum reduzieren und alten, bewährten, Technologien den Vorrang geben.
Meine Frau und ich werden die Anwendung zum selben Zeitpunkt nutzen und möchten die Änderungen vom jeweils anderen mitbekommen. Da es keine großen Anforderungen an Rechenleistung und Grafik gibt, bietet sich eine Webanwendung an. Implementiert wird sie in der reinsten Form, der Server sendet HTML an den Browser und dieser zeigt es an.
So wenig wie eine Single Page Application Architektur zum Einsatz kommt, fehlen auch andere „moderne“ Technologien. Kein Framework wie React, Vue oder Svelte und auch kein TypeScript und Sass. Stattdessen erfolgt die Umsetzung in Vanilla HTML, CSS und JavaScript. Damit ist garantiert, dass auch in 50 Jahren eine direkte Weiterentwicklung ohne Veränderungen am Entwicklungswerkzeug erfolgen kann.
Bei der Datenbankwahl war bisher meine Standardantwort PostgreSQL. Ein großartiges Datenbankmanagementsystem an dem es für mich keinen Kritikpunkt gibt. Im Sinne von Robuster Software ist jedoch SQLite wahrscheinlich die bessere Wahl.
Diese Erkenntnis schmeckt mir noch nicht ganz, es ist aber an der Zeit sich selbst an das zu halten, was man predigt. Und hier scheint die Rechnung eindeutig. Wenn SQLite und PostgreSQL beide die Anforderungen erfüllen, ist SQLite der eindeutige Gewinner. Die Datenbank ist direkt in die Anwendung integriert und es gibt keine zusätzlichen Komponenten, die Aufmerksamkeit benötigen.
Für die Webanwendung ist die Wahl auf die Programmiersprache Go gefallen. Im Vergleich zu interpretierten Programmiersprachen wird die kompilierte Anwendung so lange auf dem Server laufen, bis sich die darunterliegende Architektur verändert. Und selbst dann bin ich bei einer erneuten Kompilierung zuversichtlich. Go hat in der Vergangenheit eine ausgezeichnete Rückwärtskompatibilität demonstriert.
Außerdem besitzt die Programmiersprache eine umfangreiche Standardbibliothek. Für die Umsetzung einer Webanwendung braucht es wenige bis keine Komponenten von Dritten. Das Zusammenspiel von Go und SQLite erfolgt ebenfalls ohne Ballast. Die Datenbankabfragen werden alle direkt in SQL geschrieben.
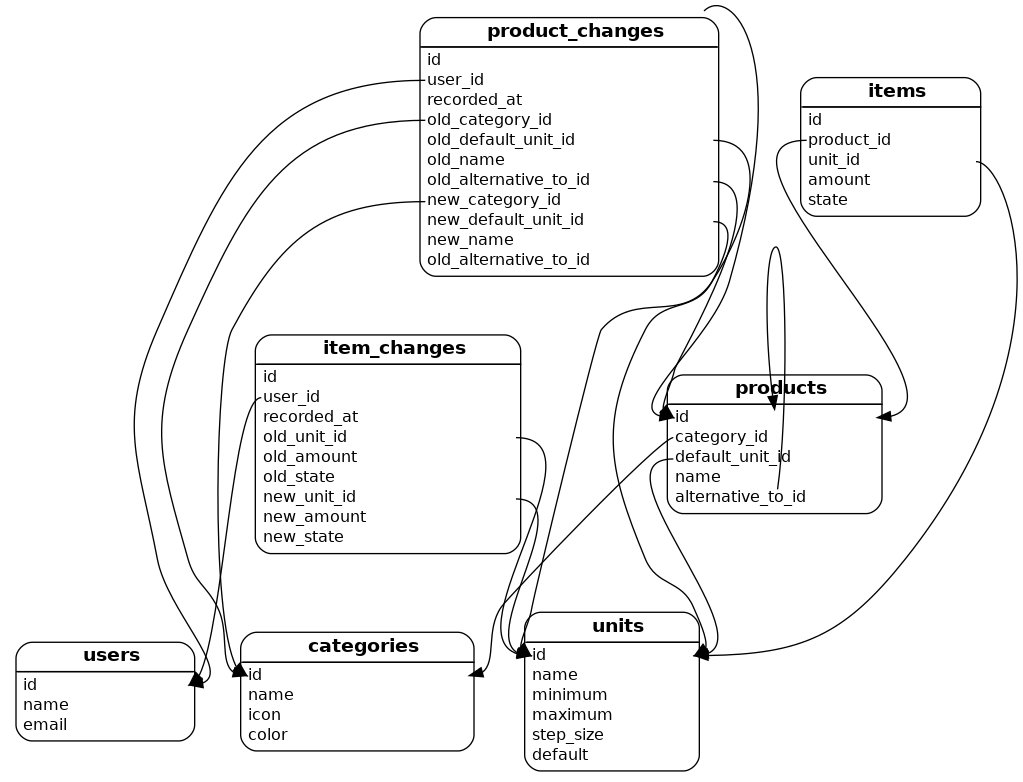
Während der Umsetzung ist es zu diversen Änderungen am Datenbankschema gekommen. Die Modellierung von Maßeinheiten und Größen hat sich mehrfach verändert. Es hat mehrere Anläufe benötigt, bis eine pragmatische Lösung gefunden wurde, die den nötigen Detailgrad bietet, ohne zu komplex zu sein.
Im Rahmen dieser Experimente hat sich auch die Notwendigkeit von doppelten Namensspalten für Produkte und Größen herauskristallisiert. Je nach Menge wird dann der Singular oder Plural Name angezeigt.
Was in der Grafik nicht zu sehen ist, sind die Indizes, Checks und Constraints, die sicherstellen, dass es zu keinen Dateninkonsistenzen kommt. Zum Beispiel garantiert ein Teilindex, dass es keine doppelten Einträge auf der Einkaufsliste mit identischer Maßeinheit gibt.
Um das Schreiben der Einkaufsliste zu beschleunigen, war die Idee, ein Autocomplete für existierende Produkte zu verwenden. Mein Widerwille, eine JavaScript-Bibliothek von Dritten als Abhängigkeit hinzuzufügen und die Sinnlosigkeit eine selbst zu schreiben hat mich auf eine Idee gebracht.
CSS Attributselektoren wie [attr*=wert] kombiniert mit ein wenig JavaScript sollten in meiner Situation funktionieren. Es stellte sich nur die Frage ob die Lösung schnell genug für das iPhone 5S ist.
Um diesen potentiellen Flaschenhals zu überprüfen wurden 1.000 zufällige Produktnamen generiert und das Autocomplete auf dem iPhone 5S meiner Frau ausprobiert.
Zu meiner Freude funktionierte es tadellos. Damit war das Thema Autocomplete mit 20 Zeilen JavaScript und ohne Abhängigkeiten erledigt.
Komplexe Bedienelemente und Interaktionen sind eine Sache der Vergangenheit. Wie bei so vielem ist auch in der Formulargestaltung weniger mehr. Adam Silvers Form Desing Masterclass Workshop und unzählige Blogartikel haben mich gelehrt, worauf es bei bedienbaren Formularen ankommt. Diesem Rat versuche ich so gut es geht zu folgen. Dass dadurch die Umsetzung einfacher wird, ist ein hervorragender Bonus.
Die Inspiration für Fehlermeldungen und Optik kommt vom GOV.UK Design System. Es ist beeindruckend, wie viel Sorgfalt und Überlegungen dort hineinfließen.
Mit der technischen Implementierung von Formularen bin ich noch nicht ganz glücklich. Im Moment werden für jedes neue Formularfeld ~15 Zeilen HTML kopiert. Das löst den Wunsch nach Hilfsfunktionen aus. Gleichzeitig will ich nicht in die Falle von Künstlicher Komplexität tappen und eine (unnötige) Abstraktionsschicht erschaffen.
Abfragen sollten immer idempotent implementiert sein. Eine Abfrage verändert keine Daten im System. Sie kann beliebig oft gemacht werden und der Zustand der Anwendung verändert sich nicht. Bei Anweisungen sieht das anders aus. In der Regel ist es dort das Ziel, eine Veränderung zu bewirken.
Durch den Zurück-Button eines Browsers oder der Wiederholung von HTTP-Requests durch eine schlechte Netzwerkverbindung kann es passieren, dass eine Anweisung fälschlicherweise mehrfach gegeben wird.
Wenn im Fall der Einkaufsliste das Formular für das Hinzufügen eines Produktes doppelt abgeschickt wird und beide Anweisungen verarbeitet werden, würde am Ende die falsche Menge auf der Einkaufsliste stehen. Um das zu verhindern, werden Idempotency Keys verwendet, ein Konzept, das ich bei Brandur aufgeschnappt habe.
Dafür wird in jedem Formular ein verstecktes Feld mit einem einzigartigen Zufallswert hinzugefügt. Dieser Wert wird in der Transaktion der regulären Daten mit in die Datenbank geschrieben. Ein Index garantiert, dass der Wert einzigartig ist. Beim doppeltem Abschicken des Formulars kann ein solcher Fehler erkannt werden, um dann die Transaktion zurückzurollen und die Datenkorruption zu verhindern.
Damit die Chancen auf eine Kollision beim Zufallswert nicht steigen, werden regelmäßig alte Werte aus der Datenbank gelöscht.
Für den Leistungstest habe ich ein kleines Programm geschrieben, das eine bestimmte Menge an Beispieldaten generiert und in die Datenbank schreibt. Die unter Dimensionierung des Systems festgelegten Limits dienten dazu als Anhaltspunkt. Anschließend habe ich die Anwendung gestartet und die Funktionalität manuell getestet.
Dabei hat sich eine Problemstelle gezeigt. Auf dem Screen, wo die Einkaufsliste geschrieben wird, werden bereits hinzugefügte Einträge aufgelistet. Diese sind absteigend basierend auf der letzten Änderung sortiert. Mit den generierten Beispieldaten dauerte die Abfrage für diese Liste plötzlich 2 Sekunden.
Der Zeitpunkt der letzten Änderung eines Eintrags wird von allen Änderungen dieses Eintrags abgeleitet. Die anderen Abfragen hatten eine natürliche WHERE Bedingung, die die Menge an Zeilen einschränkt, die relevant sind. SQLite hat dadurch eine schnelle SEARCH Instruktion verwenden können. Bei der langsamen Abfrage gibt es jedoch keine Bedingung. Alle Zeilen könnten relevant sein. Deshalb musste SQLite für die gesamte Tabelle den Zeitpunkt der letzten Änderung berechnen und dann eine kostspielige SCAN Instruktion verwenden.
Da ich nicht in der Lage war diese Grundproblematik zu lösen und schnelleres SQL zu schreiben, entschied ich mich für eine pragmatische Lösung, die das Datenbankschema verändert. Statt den Zeitpunkt der letzten Änderung von allen Änderungen eines Eintrages abzuleiten, wird der Zeitpunkt direkt pro Eintrag gespeichert und aktuell gehalten.
Mit dieser Änderung ist sichergestellt, dass die Anwendung in 50 Jahren genauso blitzschnell ist, wie am ersten Tag.
Die Anwendung hat nur https://github.com/mattn/go-sqlite3 und golangcollege/sessions als direkte Abhängigkeiten. Der eigene Quellcode beläuft sich auf 3.500 Zeilen. Die großen Teile davon sind:
Die 50 Commits verteilen sich auf einen Zeitraum vom 10. Dezember 2021 bis zum 16. Juli 2022. Insgesamt wurde jedoch nur an 20 Tagen an der Anwendung gearbeitet.
Ich habe leider keine Zeiterfassung betrieben und kann deshalb keine exakte Angabe zur Menge an Arbeitsstunden machen. Bei meiner Arbeitsweise halte ich es jedoch realistisch, für jeden Commit im Schnitt mit einer Stunde zu rechnen.
Während der Umsetzung des Projektes gab es diverse technische Herausforderungen, die mich gezwungen haben, Neues zu lernen und meinen Horizont zu erweitern. Wichtige Erkenntnisse konnte ich auch zu meinem Zugang zur Entwicklung von Webanwendungen gewinnen.
Auf der Einkaufsliste werden Einträge alphabetisch sortiert. Damit SQLite die beiden Wörter „Apfel“ und „Äpfel“ in die korrekte Reihenfolge gibt, muss man exakt definieren, wie das funktioniert. In SQLite passiert das über sogenannte „Collating Sequences“, die definiert werden können.
Um diese Arbeit nicht selbst machen zu müssen, kann man sich der „International Components for Unicode“ Bibliothek (ICU) bedienen. Kombiniert mit der SQLite Extension sqlite_icu können dann vordefinierte Collating Sequences geladen und verwendet werden: SELECT icu_load_collation('de_AT', 'de_AT');.
Ich war unvorbereitet und überrascht, wie dieses Thema in SQLite gelöst wird. Es hat einige Zeit gedauert, bis ich es verstanden und implementiert hatte. Bis heute bin ich mir nicht sicher, ob ich alles „richtig“ gemacht habe. Die Handhabung kommt mir nämlich ein wenig zu umständlich vor.
Die vom Betriebssystem bereitgestellte SQLite CLI muss mit der sqlite_icu Extension kompiliert worden sein, sonst kann mit der Datenbank nicht gearbeitet werden. Alternativ muss sich jeder im Team die CLI selbst kompilieren.
Außerdem muss jede Datenbankverbindung icu_load_collation verwenden, um die korrekten Collating Sequences zu laden, bevor SQL Abfragen gemacht werden können.
Mir kommt das alles impraktikabel vor. Die Chancen sind hoch, dass ich etwas falsch mache. Ich würde liebend gerne mit jemandem sprechen, der sich damit auskennt, um herauszufinden, was ich besser machen kann.
Ich verwende eine nix-shell, um die Abhängigkeiten meiner Projekte in einer isolierten Umgebung bereitzustellen. Meine anfängliche Begeisterung wird leider zunehmend durch, in meinen Augen, unnötige Probleme getrübt. So auch in diesem Projekt.
Go ermöglicht es statisch verlinkte Programme zu erstellen. Diese Möglichkeit wollte ich nutzen, da es perfekt für Deployments ist. Alles, was meine Webanwendung benötigt, ist direkt in der ausführbaren Datei enthalten.
Durch die Verwendung von SQLite besteht das Projekt nicht aus purem Go Quellcode. Deshalb braucht es beim Kompilieren auch CGO, um SQLite, ICU und die verwendete Extension erstellen zu können.
In Kombination mit der nix-shell hat sich das für mich als unüberwindbares Hindernis entpuppt. Egal, welche undurchsichtigen Kompilierungs-Einstellungen und Nix Konfigurationen ich getroffen habe, das Ergebnis war immer dasselbe. Ich war nicht in der Lage, einen statischen Go Build meiner Anwendung zu erstellen.
Nach vielen Stunden Frust habe ich entnervt aufgegeben und akzeptiert, dass ich die Anwendung einfach direkt auf dem Server kompiliere und nur dynamisch verlinke.
Ein oft genannter Vorteil von Single Page Applications ist die Geschwindigkeit, mit der die Benutzeroberfläche reagiert. Die HTTP Requests finden im Hintergrund statt, sodass sich die Benutzeroberfläche in den meisten Fällen schon vorab aktualisieren kann. Dadurch fühlt sich die Anwendung schnell an.
Bei einer Webanwendung wie hier ist das nicht möglich. Jede Interaktion lädt eine neue HTML Seite vom Server. In einem Supermarkt mit 3G könnte das so langsam sein, dass die gesamte Anwendung unbenutzbar wird.
Die erste Verwendung zeigte, dass diese Bedenken unbegründet sind. Das vollständige Laden vom Server ist schnell genug. Die Benutzeroberfläche ist schnell und kein Hindernis bei der Benutzung.
Folgende Videos wurden während echten Einkaufstouren aufgezeichnet. Um die Videolänge zu kürzen, wurden lediglich die Pausen, wo ich mich im Geschäft bewegt habe, herausgeschnitten.
Es werden keine ausgefallenen Techniken verwendet, um diese Geschwindigkeit zu erreichen. Das Geheimnis ist ein sparsamer Umgang mit HTML, CSS und JS in Kombination mit GZip und einer schnellen Anwendung.
Der Auslöser für die Entwicklung dieser Webanwendung war Datenkorruption und Datenverlust in der ursprünglich verwendeten App Überliste. Es gab auch keine Möglichkeit, nachzuvollziehen, was passiert ist. Plötzlich war ein Eintrag von der Liste verschwunden und niemand wusste wieso.
Deshalb habe ich von Beginn an einen Verlauf aller Änderungen angedacht. Im Prinzip einen Auditlog, um feststellen zu können, wer wann, welche Anweisung gegeben hat.
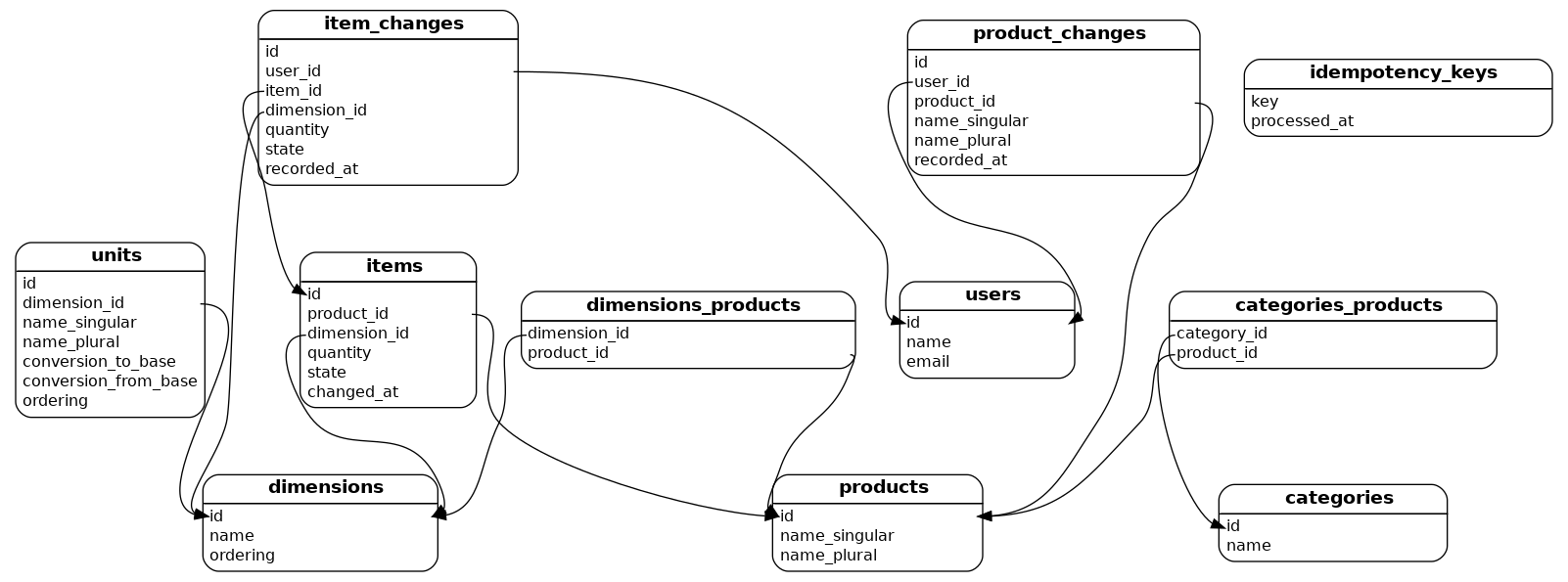
Im Datenbankschema sind dafür die Tabellen product_changes und item_changes vorgesehen. Diese werden bereits korrekt befüllt, jedoch noch nicht ausgelesen. In der Benutzeroberfläche gibt es keinen Ort, wo man diesen Verlauf sehen kann. Ich bin noch nicht dazugekommen, diese Funktionalität zu implementieren.
Vermutlich werde ich es auch niemals tun und stattdessen sogar das Datenbankschema bereinigen sowie den entsprechenden Quellcode für das Befüllen löschen.
Der Echtbetrieb hat nämlich gezeigt, dass die neue Webanwendung korrekt funktioniert. Es gab keinen Datenverlust oder unerklärliche Datenkorruption. Der Wunsch nach einem Verlauf ist vollständig verflogen. Die zusätzlichen Informationen werden nicht benötigt, weil das System korrekt funktioniert.
Ich bin ausgesprochen zufrieden mit dem Ergebnis. Bei jedem Einkauf freue ich mich über die Besserliste. Der Vergleich zwischen Überliste und Besserliste hat mir verdeutlicht, wie negativ sich mangelhafte Software auf unser Leben auswirkt.
Es hat mich außerdem bestätigt, dass an der Idee von Robuster Software etwas dran ist. Der wohlüberlegte Einsatz von Technologie ebnet den Weg für bessere Software. Es schafft Raum, um sich mit den zugrundeliegenden Bedürfnissen zu beschäftigen und etwas für andere Menschen zu erschaffen. Ein erfüllendes Gefühl, das wesentlich länger anhält, als das Meistern einer neuen Technologie.
Du hast Fragen, Ideen oder Anregungen? Ich lese gerne von dir und freue mich auf einen Austausch von Gedanken. Schreib mir an david@strauss.io und sag „Hallo“.